Support for Multi-core/Multi-thread Architectures
Contents
- Definitions
- Overview of srun flags
- Motivation behind high-level srun flags
- Extensions to sinfo/squeue/scontrol
- Configuration settings in slurm.conf
Definitions
- BaseBoard
- Also called motherboard.
- LDom
- Locality domain or NUMA domain. May be equivalent to BaseBoard or Socket.
- Socket/Core/Thread
- Figure 1 illustrates the notion of Socket, Core and Thread as it is defined in Slurm's multi-core/multi-thread support documentation.
- CPU
- Depending upon system configuration, this can be either a core or a thread.
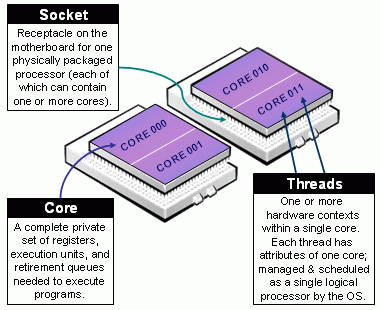
Figure 1: Definitions of Socket, Core, & Thread
- Affinity
- The state of being bound to a specific logical processor.
- Affinity Mask
- A bitmask where indices correspond to logical processors. The least significant bit corresponds to the first logical processor number on the system, while the most significant bit corresponds to the last logical processor number on the system. A '1' in a given position indicates a process can run on the associated logical processor.
- Fat Masks
- Affinity masks with more than 1 bit set allowing a process to run on more than one logical processor.
Overview of srun flags
Many flags have been defined to allow users to better take advantage of this architecture by explicitly specifying the number of sockets, cores, and threads required by their application. Table 1 summarizes these options.
| Low-level (explicit binding) | |
| --cpu-bind=... | Explicit process affinity binding and control options |
| High-level (automatic mask generation) | |
| --sockets-per-node=S | Number of sockets in a node to dedicate to a job (minimum) |
| --cores-per-socket=C | Number of cores in a socket to dedicate to a job (minimum) |
| --threads-per-core=T | Minimum number of threads in a core to dedicate to a job. In task layout, use the specified maximum number of threads per-core. |
| -B S[:C[:T]] | Combined shortcut option for --sockets-per-node, --cores-per_cpu, --threads-per_core |
| Task Distribution Options | |
| -m / --distribution | Distributions of: arbitrary | block | cyclic | plane=x | [block|cyclic]:[block|cyclic|fcyclic] |
| Memory as a consumable resource | |
| --mem=mem | amount of real memory per node required by the job. |
| --mem-per-cpu=mem | amount of real memory per allocated CPU required by the job. |
| Task invocation control | |
| --cpus-per-task=CPUs | number of CPUs required per task | --ntasks-per-node=ntasks | number of tasks to invoke on each node | --ntasks-per-socket=ntasks | number of tasks to invoke on each socket | --ntasks-per-core=ntasks | number of tasks to invoke on each core | --overcommit | Permit more than one task per CPU |
| Application hints | |
| --hint=compute_bound | use all cores in each socket | --hint=memory_bound | use only one core in each socket | --hint=[no]multithread | [don't] use extra threads with in-core multi-threading |
| Resources reserved for system use | |
| --core-spec=cores | Count of cores to reserve for system use | --thread-spec=threads | Count of threads to reserve for system use |
It is important to note that many of these flags are only meaningful if the processes have some affinity to specific CPUs and (optionally) memory. Inconsistent options generally result in errors. Task affinity is configured using the TaskPlugin parameter in the slurm.conf file. Several options exist for the TaskPlugin depending upon system architecture and available software, any of them except "task/none" will bind tasks to CPUs. See the "Task Launch" section if generating slurm.conf via configurator.html.
Low-level --cpu-bind=... - Explicit binding interface
The following srun flag provides a low-level core binding interface:
--cpu-bind= Bind tasks to CPUs
q[uiet] quietly bind before task runs (default)
v[erbose] verbosely report binding before task runs
no[ne] don't bind tasks to CPUs (default)
rank bind by task rank
map_cpu:<list> specify a CPU ID binding for each task
where <list> is
<cpuid1>,<cpuid2>,...<cpuidN>
mask_cpu:<list> specify a CPU ID binding mask for each
task where <list> is
<mask1>,<mask2>,...<maskN>
rank_ldom bind task by rank to CPUs in a NUMA
locality domain
map_ldom:<list> specify a NUMA locality domain ID
for each task where <list> is
<ldom1>,<ldom2>,...<ldomN>
rank_ldom bind task by rank to CPUs in a NUMA
locality domain where <list> is
<ldom1>,<ldom2>,...<ldomN>
mask_ldom:<list> specify a NUMA locality domain ID mask
for each task where <list> is
<ldom1>,<ldom2>,...<ldomN>
boards auto-generated masks bind to boards
ldoms auto-generated masks bind to NUMA locality
domains
sockets auto-generated masks bind to sockets
cores auto-generated masks bind to cores
threads auto-generated masks bind to threads
help show this help message
The affinity can be either set to either a specific logical processor (socket, core, threads) or at a coarser granularity than the lowest level of logical processor (core or thread). In the later case the processes are allowed to utilize multiple processors within a specific socket or core.
Examples:
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x1,0x4 a.out
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x3,0xD a.out
See also 'srun --cpu-bind=help' and 'man srun'
High-level -B S[:C[:T]] - Automatic mask generation interface
We have updated the node selection infrastructure with a mechanism that allows selection of logical processors at a finer granularity. Users are able to request a specific number of nodes, sockets, cores, and threads:
-B --extra-node-info=S[:C[:T]] Expands to:
--sockets-per-node=S number of sockets per node to allocate
--cores-per-socket=C number of cores per socket to allocate
--threads-per-core=T number of threads per core to allocate
each field can be 'min' or wildcard '*'
Total cpus requested = (Nodes) x (S x C x T)
Examples:
- srun -n 8 -N 4 -B 2:1 a.out
- srun -n 8 -N 4 -B 2 a.out
note: compare the above with the previous corresponding --cpu-bind=... examples - srun -n 16 -N 4 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
or - srun -n 16 -N 4 --sockets-per-node=2 --cores-per-socket=2 --threads-per-core=1 a.out
- srun -n 16 -N 2-4 -B '1:*:1' a.out
- srun -n 16 -N 4-2 -B '2:*:1' a.out
- srun -n 16 -N 4-4 -B '1:1' a.out
Notes:
- Adding --cpu-bind=no to the command line will cause the processes to not be bound the logical processors.
- Adding --cpu-bind=verbose to the command line (or setting the CPU_BIND environment variable to "verbose") will cause each task to report the affinity mask in use
- Binding is on by default when -B is used. The default binding on multi-core/multi-threaded systems is equivalent to the level of resource enumerated in the -B option.
See also 'srun --help' and 'man srun'
Task distribution options: Extensions to -m / --distribution
The -m / --distribution option for distributing processes across nodes
has been extended to also describe the distribution within the lowest level
of logical processors.
Available distributions include:
arbitrary | block | cyclic | plane=x | [block|cyclic]:[block|cyclic|fcyclic]
The plane distribution (plane=x) results in a block:cyclic distribution of blocksize equal to x. In the following we use "lowest level of logical processors" to describe sockets, cores or threads depending of the architecture. The distribution divides the cluster into planes (including a number of the lowest level of logical processors on each node) and then schedule first within each plane and then across planes.
For the two dimensional distributions ([block|cyclic]:[block|cyclic|fcyclic]), the second distribution (after ":") allows users to specify a distribution method for processes within a node and applies to the lowest level of logical processors (sockets, core or thread depending on the architecture). When a task requires more than one CPU, the cyclic will allocate all of those CPUs as a group (i.e. within the same socket if possible) while fcyclic would distribute each of those CPU of the in a cyclic fashion across sockets.
The binding is enabled automatically when high level flags are used as long as the task/affinity plug-in is enabled. To disable binding at the job level use --cpu-bind=no.
The distribution flags can be combined with the other switches:
- srun -n 16 -N 4 -B '2:*:1' -m block:cyclic --cpu-bind=socket a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 --cpu-bind=core a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 a.out
The default distribution on multi-core/multi-threaded systems is equivalent to -m block:cyclic with --cpu-bind=thread.
See also 'srun --help'
Memory as a Consumable Resource
The --mem flag specifies the maximum amount of memory in MB needed by the job per node. This flag is used to support the memory as a consumable resource allocation strategy.
--mem=MB maximum amount of real memory per node
required by the job.
This flag allows the scheduler to co-allocate jobs on specific nodes given that their added memory requirement do not exceed the total amount of memory on the nodes.
In order to use memory as a consumable resource, the select/cons_res plugin must be first enabled in slurm.conf:
SelectType=select/cons_res # enable consumable resources SelectTypeParameters=CR_Memory # memory as a consumable resource
Using memory as a consumable resource is typically combined with the CPU, Socket, or Core consumable resources using SelectTypeParameters values of: CR_CPU_Memory, CR_Socket_Memory or CR_Core_Memory
See the "Resource Selection" section if generating slurm.conf via configurator.html.
See also 'srun --help' and 'man srun'
Task invocation as a function of logical processors
The --ntasks-per-{node,socket,core}=ntasks flags allow the user to request that no more than ntasks be invoked on each node, socket, or core. This is similar to using --cpus-per-task=ncpus but does not require knowledge of the actual number of cpus on each node. In some cases, it is more convenient to be able to request that no more than a specific number of ntasks be invoked on each node, socket, or core. Examples of this include submitting an app where only one "task/rank" should be assigned to each node while allowing the job to utilize all of the parallelism present in the node, or submitting a single setup/cleanup/monitoring job to each node of a pre-existing allocation as one step in a larger job script. This can now be specified via the following flags:
--ntasks-per-node=n number of tasks to invoke on each node --ntasks-per-socket=n number of tasks to invoke on each socket --ntasks-per-core=n number of tasks to invoke on each core
For example, given a cluster with nodes containing two sockets, each containing two cores, the following commands illustrate the behavior of these flags:
% srun -n 4 hostname hydra12 hydra12 hydra12 hydra12 % srun -n 4 --ntasks-per-node=1 hostname hydra12 hydra13 hydra14 hydra15 % srun -n 4 --ntasks-per-node=2 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-socket=1 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-core=1 hostname hydra12 hydra12 hydra12 hydra12
See also 'srun --help' and 'man srun'
Application hints
Different applications will have various levels of resource requirements. Some applications tend to be computationally intensive but require little to no inter-process communication. Some applications will be memory bound, saturating the memory bandwidth of a processor before exhausting the computational capabilities. Other applications will be highly communication intensive causing processes to block awaiting messages from other processes. Applications with these different properties tend to run well on a multi-core system given the right mappings.
For computationally intensive applications, all cores in a multi-core system would normally be used. For memory bound applications, only using a single core on each socket will result in the highest per core memory bandwidth. For communication intensive applications, using in-core multi-threading (e.g. hyperthreading, SMT, or TMT) may also improve performance. The following command line flags can be used to communicate these types of application hints to the Slurm multi-core support:
--hint= Bind tasks according to application hints
compute_bound use all cores in each socket
memory_bound use only one core in each socket
[no]multithread [don't] use extra threads with in-core multi-threading
help show this help message
For example, given a cluster with nodes containing two sockets, each containing two cores, the following commands illustrate the behavior of these flags. In the verbose --cpu-bind output, tasks are described as 'hostname, task Global_ID Local_ID [PID]':
% srun -n 4 --hint=compute_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15425]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15426]: mask 0x4 set cpu-bind=MASK - hydra12, task 2 2 [15427]: mask 0x2 set cpu-bind=MASK - hydra12, task 3 3 [15428]: mask 0x8 set % srun -n 4 --hint=memory_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15550]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15551]: mask 0x4 set cpu-bind=MASK - hydra13, task 2 0 [14974]: mask 0x1 set cpu-bind=MASK - hydra13, task 3 1 [14975]: mask 0x4 set
See also 'srun --hint=help' and 'man srun'
Motivation behind high-level srun flags
The motivation behind allowing users to use higher level srun flags instead of --cpu-bind is that the later can be difficult to use. The proposed high-level flags are easier to use than --cpu-bind because:
- Affinity mask generation happens automatically when using the high-level flags.
- The length and complexity of the --cpu-bind flag vs. the length of the combination of -B and --distribution flags make the high-level flags much easier to use.
Also as illustrated in the example below it is much simpler to specify a different layout using the high-level flags since users do not have to recalculate mask or CPU IDs. This approach is much simpler than rearranging the mask or map.
Given a 32-process job and a four node, dual-socket, dual-core cluster, we want to use a block distribution across the four nodes and then a cyclic distribution within the node across the physical processors. Below we show how to obtain the wanted layout using 1) high-level flags and 2) --cpubind
High-Level flags
Using Slurm's high-level flag, users can obtain the above layout with either of the following submissions since --distribution=block:cyclic is the default distribution method.
$ srun -n 32 -N 4 -B 4:2 --distribution=block:cyclic a.outor
$ srun -n 32 -N 4 -B 4:2 a.out
The cores are shown as c0 and c1 and the processors are shown as p0 through p3. The resulting task IDs are:
|
|
The computation and assignment of the task IDs is transparent to the user. Users don't have to worry about the core numbering (Section Pinning processes to cores) or any setting any CPU affinities. By default CPU affinity will be set when using multi-core supporting flags.
Low-level flag --cpu-bind
Using Slurm's --cpu-bind flag, users must compute the CPU IDs or masks as well as make sure they understand the core numbering on their system. Another problem arises when core numbering is not the same on all nodes. The --cpu-bind option only allows users to specify a single mask for all the nodes. Using Slurm high-level flags remove this limitation since Slurm will correctly generate the appropriate masks for each requested nodes.
On a four dual-socket dual-core node cluster with core block numbering
The cores are shown as c0 and c1 and the processors are shown as p0 through p3. The CPU IDs within a node in the block numbering are: (this information is available from the /proc/cpuinfo file on the system)
|
|
resulting in the following mapping for processor/cores and task IDs which users need to calculate:
|
|
|
|
The above maps and task IDs can be translated into the following command:
$ srun -n 32 -N 4 --cpu-bind=mask_cpu:1,4,10,40,2,8,20,80 a.outor
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
Same cluster but with its core numbered cyclic instead of block
On a system with cyclically numbered cores, the correct mask argument to the srun command looks like: (this will achieve the same layout as the command above on a system with core block numbering.)
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,1,2,3,4,5,6,7 a.out
Block map_cpu on a system with cyclic core numbering
If users do not check their system's core numbering before specifying the map_cpu list and thereby do not realize that the system has cyclic core numbering instead of block numbering then they will not get the expected layout. For example, if they decide to re-use their command from above:
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
they get the following unintentional task ID layout:
|
|
since the processor IDs within a node in the cyclic numbering are:
|
|
The important conclusion is that using the --cpu-bind flag is not trivial and that it assumes that users are experts.
Extensions to sinfo/squeue/scontrol
Several extensions have also been made to the other Slurm utilities to make working with multi-core/multi-threaded systems easier.
sinfo
The long version (-l) of the sinfo node listing (-N) has been extended to display the sockets, cores, and threads present for each node. For example:
% sinfo -N NODELIST NODES PARTITION STATE hydra[12-15] 4 parts* idle % sinfo -lN Thu Sep 14 17:47:13 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-15] 4 parts* idle 8+ 2+:4+:1+ 2007 41447 1 (null) none % sinfo -lNe Thu Sep 14 17:47:18 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-14] 3 parts* idle 8 2:4:1 2007 41447 1 (null) none hydra15 1 parts* idle 64 8:4:2 2007 41447 1 (null) none
For user specified output formats (-o/--format) and sorting (-S/--sort), the following identifiers are available:
%X Number of sockets per node
%Y Number of cores per socket
%Z Number of threads per core
%z Extended processor information: number of
sockets, core, threads (S:C:T) per node
For example:
% sinfo -o '%9P %4c %8z %8X %8Y %8Z' PARTITION CPUS S:C:T SOCKETS CORES THREADS parts* 4 2:2:1 2 2 1
See also 'sinfo --help' and 'man sinfo'
squeue
For user specified output formats (-o/--format) and sorting (-S/--sort), the following identifiers are available:
%m Size of memory (in MB) requested by the job
%H Number of requested sockets per node
%I Number of requested cores per socket
%J Number of requested threads per core
%z Extended processor information: number of requested
sockets, cores, threads (S:C:T) per node
Below is an example squeue output after running 7 copies of:
- % srun -n 4 -B 2:2:1 --mem=1024 sleep 100 &
% squeue -o '%.5i %.2t %.4M %.5D %7H %6I %7J %6z %R' JOBID ST TIME NODES SOCKETS CORES THREADS S:C:T NODELIST(REASON) 17 PD 0:00 1 2 2 1 2:2:1 (Resources) 18 PD 0:00 1 2 2 1 2:2:1 (Resources) 19 PD 0:00 1 2 2 1 2:2:1 (Resources) 13 R 1:27 1 2 2 1 2:2:1 hydra12 14 R 1:26 1 2 2 1 2:2:1 hydra13 15 R 1:26 1 2 2 1 2:2:1 hydra14 16 R 1:26 1 2 2 1 2:2:1 hydra15
The squeue command can also display the memory size of jobs, for example:
% sbatch --mem=123 tmp Submitted batch job 24 $ squeue -o "%.5i %.2t %.4M %.5D %m" JOBID ST TIME NODES MIN_MEMORY 24 R 0:05 1 123
See also 'squeue --help' and 'man squeue'
scontrol
The following job settings can be adjusted using scontrol:
Requested Allocation: ReqSockets=<count> Set the job's count of required sockets ReqCores=<count> Set the job's count of required cores ReqThreads=<count> Set the job's count of required threads
For example:
# scontrol update JobID=17 ReqThreads=2 # scontrol update JobID=18 ReqCores=4 # scontrol update JobID=19 ReqSockets=8 % squeue -o '%.5i %.2t %.4M %.5D %9c %7H %6I %8J' JOBID ST TIME NODES MIN_PROCS SOCKETS CORES THREADS 17 PD 0:00 1 1 4 2 1 18 PD 0:00 1 1 8 4 2 19 PD 0:00 1 1 4 2 1 13 R 1:35 1 0 0 0 0 14 R 1:34 1 0 0 0 0 15 R 1:34 1 0 0 0 0 16 R 1:34 1 0 0 0 0
The 'scontrol show job' command can be used to display the number of allocated CPUs per node as well as the socket, cores, and threads specified in the request and constraints.
% srun -N 2 -B 2:1 sleep 100 & % scontrol show job 20 JobId=20 UserId=(30352) GroupId=users(1051) Name=sleep Priority=4294901749 Partition=parts BatchFlag=0 AllocNode:Sid=hydra16:3892 TimeLimit=UNLIMITED JobState=RUNNING StartTime=09/25-17:17:30 EndTime=NONE NodeList=hydra[12-14] NodeListIndices=0,2,-1 AllocCPUs=1,2,1 NumCPUs=4 ReqNodes=2 ReqS:C:T=2:1:* OverSubscribe=0 Contiguous=0 CPUs/task=0 MinCPUs=0 MinMemory=0 MinTmpDisk=0 Features=(null) Dependency=0 Account=(null) Reason=None Network=(null) ReqNodeList=(null) ReqNodeListIndices=-1 ExcNodeList=(null) ExcNodeListIndices=-1 SubmitTime=09/25-17:17:30 SuspendTime=None PreSusTime=0
See also 'scontrol --help' and 'man scontrol'
Configuration settings in slurm.conf
Several slurm.conf settings are available to control the multi-core features described above.
In addition to the description below, also see the "Task Launch" and "Resource Selection" sections if generating slurm.conf via configurator.html.
As previously mentioned, in order for the affinity to be set, the task/affinity plugin must be first enabled in slurm.conf:
TaskPlugin=task/affinity # enable task affinity
This setting is part of the task launch specific parameters:
# o Define task launch specific parameters # # "TaskProlog" : Define a program to be executed as the user before each # task begins execution. # "TaskEpilog" : Define a program to be executed as the user after each # task terminates. # "TaskPlugin" : Define a task launch plugin. This may be used to # provide resource management within a node (e.g. pinning # tasks to specific processors). Permissible values are: # "task/affinity" : CPU affinity support # "task/cgroup" : bind tasks to resources using Linux cgroup # "task/none" : no task launch actions, the default # # Example: # # TaskProlog=/usr/local/slurm/etc/task_prolog # default is none # TaskEpilog=/usr/local/slurm/etc/task_epilog # default is none # TaskPlugin=task/affinity # default is task/none
Declare the node hardware configuration in slurm.conf:
NodeName=dualcore[01-16] CoresPerSocket=2 ThreadsPerCore=1
For a more complete description of the various node configuration options see the slurm.conf man page.
Last modified 22 April 2021