Cloud Scheduling Guide
Overview
Slurm has the ability to support a cluster that grows and shrinks on demand, typically relying upon a service such as Amazon Elastic Computing Cloud (Amazon EC2), Google Cloud Platform or Microsoft Azure for resources. These resources can be combined with an existing cluster to process excess workload (cloud bursting) or it can operate as an independent self-contained cluster. Good responsiveness and throughput can be achieved while you only pay for the resources needed.
The rest of this document describes details about Slurm's infrastructure that can be used to support cloud scheduling.
Slurm's cloud scheduling logic relies heavily upon the existing power save logic. Review of Slurm's Power Saving Guide is strongly recommended. This logic initiates programs when nodes are required for use and another program when those nodes are no longer required. For cloud scheduling, these programs will need to provision the resources from the cloud and notify Slurm of the node's name and network address and later relinquish the nodes back to the cloud. Most of the Slurm changes to support cloud scheduling were changes to support node addressing that can change.
Slurm Configuration
There are many ways to configure Slurm's use of resources. See the slurm.conf man page for more details about these options. Some general Slurm configuration parameters that are of interest include:
- CommunicationParameters=NoAddrCache
- By default, Slurm will cache a node's network address after successfully establishing the node's network address. This option disables the cache and Slurm will look up the node's network address each time a connection is made. This is useful, for example, in a cloud environment where the node addresses come and go out of DNS.
- ResumeFailProgram
- The program that will be executed when nodes fail to resume by ResumeTimeout. The argument to the program will be the names of the failed nodes (using Slurm's hostlist expression format).
- ResumeProgram
- The program executed when a node has been allocated and should be made
available for use. If the slurmd daemon fails to respond within the
configured SlurmdTimeout value with an updated BootTime, the node will
be placed in a DOWN state and the job requesting the node will be requeued.
If the node isn't actually rebooted (i.e. when multiple-slurmd is configured)
starting slurmd with "-b" option might be useful.
The argument to the program is the names of nodes (using Slurm's hostlist
expression format) to power up. A job to node mapping is available in JSON
format by reading the temporary file specified by the SLURM_RESUME_FILE
environment variable.
e.g.SLURM_RESUME_FILE=/proc/1647372/fd/7: { "all_nodes" : "cloud[1-3]", "jobs" : [ { "job_id" : 140814, "nodes" : "cloud[1-3]", }, { "job_id" : 140815, "nodes" : "cloud[1-2]", } ] } - PrivateData
- Including the cloud flag with PrivateData will cause cloud nodes to be visible in the output of commands like sinfo at all times. Without this flag, nodes will only be visible when the they are powered on.
- ResumeTimeout
- Maximum time permitted (in seconds) between when a node resume request is issued and when the node is actually available for use. Nodes which fail to respond in this time frame will be marked DOWN and the jobs scheduled on the node requeued. Nodes which reboot after this time frame will be marked DOWN with a reason of "Node unexpectedly rebooted." The default value is 60 seconds.
- SlurmctldParameters=cloud_dns
- By default, Slurm expects that the network addresses for cloud nodes won't be known until creation of the node and that Slurm will be notified of the node's address (e.g. scontrol update nodename=<name> nodeaddr=<addr>). Since Slurm communications rely on the node configuration found in the slurm.conf, Slurm will tell the client command, after waiting for all nodes to boot, each node's IP address. However, in environments where the nodes are in DNS, this step can be avoided by configuring this option.
- SlurmctldParameters=idle_on_node_suspend
- Mark nodes as idle, regardless of current state, when suspending nodes with SuspendProgram so that nodes will be eligible to be resumed at a later time.
- SuspendExcNodes
- Nodes not subject to suspend/resume logic. This may be used to avoid suspending and resuming nodes which are not in the cloud. Alternately the suspend/resume programs can treat local nodes differently from nodes being provisioned from cloud.
- SuspendProgram
- The program executed when a node is no longer required and can be relinquished to the cloud.
- SuspendTime
- The time interval that a node will be left idle or down before a request is made to relinquish it. Units are in seconds.
- SuspendTimeout
- Maximum time permitted (in seconds) between when a node suspend request is issued and when the node is shutdown. At that time the node must be ready for a resume request to be issued as needed for new work. The default value is 30 seconds.
- TCPTimeout
- Time permitted for TCP connections to be established. This value may need to be increased from the default (2 seconds) to account for latency between your local site and machines in the cloud.
- TreeWidth
- Since the slurmd daemons are not aware of the network addresses of other nodes in the cloud, the slurmd daemons on each node should be sent messages directly and not forward those messages between each other. To do so, configure TreeWidth to a number at least as large as the maximum node count. The value may not exceed 65533.
Some node parameters that are of interest include:
- Feature
- A node feature can be associated with resources acquired from the cloud and user jobs can specify their preference for resource use with the "--constraint" option.
- NodeName
- This is the name by which Slurm refers to the node. A name containing a numeric suffix is recommended for convenience. The NodeAddr and NodeHostname should not be set, but will be configured later using scripts.
- State
- Nodes which are to be added on demand should have a state of "CLOUD". These nodes will not actually appear in Slurm commands until after they are configured for use.
- Weight
- Each node can be configured with a weight indicating the desirability of using that resource. Nodes with lower weights are used before those with higher weights.
Nodes to be acquired on demand can be placed into their own Slurm partition. This mode of operation can be used to use these nodes only if so requested by the user. Note that jobs can be submitted to multiple partitions and will use resources from whichever partition permits faster initiation. A sample configuration in which nodes are added from the cloud when the workload exceeds available resources. Users can explicitly request local resources or resources from the cloud by using the "--constraint" option.
# Excerpt of slurm.conf SelectType=select/cons_res SelectTypeParameters=CR_CORE_Memory SuspendProgram=/usr/sbin/slurm_suspend ResumeProgram=/usr/sbin/slurm_suspend SuspendTime=600 SuspendExcNodes=tux[0-127] TreeWidth=128 NodeName=DEFAULT Sockets=1 CoresPerSocket=4 ThreadsPerCore=2 NodeName=tux[0-127] Weight=1 Feature=local State=UNKNOWN NodeName=ec[0-127] Weight=8 Feature=cloud State=CLOUD PartitionName=debug MaxTime=1:00:00 Nodes=tux[0-32] Default=yes PartitionName=batch MaxTime=8:00:00 Nodes=tux[0-127],ec[0-127] Default=no
ResumeTimeout, SuspendTimeout and SuspendTime can be applied at the partition level. If a node is in multiple partitions and these options are configured on the partitions, the higher value will be used for the node. If the option is not set, it will use the global setting. Configuring SuspendTime on a partition will enable power save mode if the global SuspendTime is not set.
By default, when power save mode is enabled Slurm attempts to "suspend" all nodes unless excluded by SuspendExcNodes or SuspendExcParts. For bursting from on-premise scenarios this can be tricky to have to remember to add on-premise nodes to the excluded options. By setting the global SuspendTime to INFINITE and configuring SuspendTime on cloud specific partitions, you can avoid having to exclude nodes.
If power save mode is enabled globally, disable power save mode for a specific partition, by setting SuspendTime to INFINITE.
Operational Details
When the slurmctld daemon starts, all nodes with a state of CLOUD will be included in its internal tables, but these node records will not be seen with user commands or used by applications until allocated to some job. After allocated, the ResumeProgram is executed and should do the following:
- Boot the node
- Configure and start Munge (depends upon configuration)
- Install the Slurm configuration file, slurm.conf, on the node. Note that configuration file will generally be identical on all nodes and not include NodeAddr or NodeHostname configuration parameters for any nodes in the cloud. Slurm commands executed on this node only need to communicate with the slurmctld daemon on the SlurmctldHost.
- Notify the slurmctld daemon of the node's hostname and network address:
scontrol update nodename=ec0 nodeaddr=123.45.67.89 nodehostname=whatever
Note that the node address and hostname information set by the scontrol command are preserved when the slurmctld daemon is restarted unless the "-c" (cold-start) option is used. - Start the slurmd daemon on the node
The SuspendProgram only needs to relinquish the node back to the cloud.
An environment variable SLURM_NODE_ALIASES contains sets of node name,
communication address and hostname.
The variable is set by salloc, sbatch, and srun.
It is then used by srun to determine the destination for job launch
communication messages.
This environment variable is only set for nodes allocated from the cloud.
If a job is allocated some resources from the local cluster and others from
the cloud, only those nodes from the cloud will appear in SLURM_NODE_ALIASES.
Each set of names and addresses is comma separated and
the elements within the set are separated by colons. For example:
SLURM_NODE_ALIASES=ec0:123.45.67.8:foo,ec2:123.45.67.9:bar
Cloud Node Lifecycle
A cloud node moves through different states when enabled with Power Saving mode. A node can have multiple states associated with it at one time. States associated with Power Saving are labeled with a symbol when viewing node details in “sinfo”.
List of Node States a cloud node may have during autoscaling operations:
| STATE | Power Saving Symbol | Description |
| IDLE | The node is not allocated to any jobs and is available for use. | |
| POWERED_DOWN | ~ | The node is powered off (node has been relinquished to the cloud). |
| ALLOCATED | All CPUS on the node have been allocated to one or more jobs. | |
| MIXED | The node has some of its CPUs allocated while others are idle. | |
| POWERING_UP | # | The node is in the process of being powered up. |
| COMPLETING | All jobs associated with this node are in the process of COMPLETING. This node state will be removed when all of the job's processes have terminated and the Slurm epilog program (if any) has terminated. | |
| POWERING_DOWN | % | The node is in the process of powering down and not capable of running any jobs. |
| DOWN | The node is unavailable for use. Slurm can automatically place nodes in this state if some failure occurs. System administrators may also explicitly place nodes in this state. If a node resumes normal operation, Slurm can automatically return it to service (See ReturnToService). A DOWN Cloud node can be changed to IDLE using the scontrol command: scontrol update node=[nodename] state=idle |
Additional states nodes can have during manual power saving operations:
| STATE | Power Saving Symbol | Description |
| DRAINING | The node is currently executing a job, but will not be allocated additional jobs. The node state will be changed to state DRAINED when the last job on it completes. Nodes enter this state per system administrator request. | |
| POWER_DOWN | ! | When the node is no longer running jobs, run the SuspendProgram. |
| DRAINED | The node is unavailable for use per system administrator request. |
A cloud node starts out in IDLE and POWERED_DOWN (~) state. In this state, no actual node exists, as the node is in the cloud waiting to be provisioned. However, the IDLE state indicates that it is eligible for work.
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 100 idle~ c1-compute-0-[0-99]
When Slurm schedules a job to a node in this state, the node will move to ALLOCATED or MIXED (based on whether all the CPUs are allocated) and POWERING_UP (#).
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 1 alloc# c1-compute-0-0> debug* up infinite 99 idle~ c1-compute-0-[1-99]
The scheduled job is in CONFIGURING state as it waits for the node to power up.
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 182 debug wrap nick_sch CF 0:01 2 c1-compute-0-0
After power up, the node registers with the Slurm controller and the POWERING_UP (#) is removed. The job will start running after the node registers + MAX of 30 seconds, based on when the node registers and job starts begin.
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 1 alloc c1-compute-0-0 debug* up infinite 99 idle~ c1-compute-0-[1-99] JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 182 debug wrap nick_sch R 0:04 2 c1-compute-0-0
Once the job completes, if no other job is scheduled to the node, the node moves to IDLE state and the timer for the SuspendTime begins. The "scontrol show node" output displays LastBusyTime, the timestamp when the node stopped running a job and became idle.
When SuspendTime is reached, the node will move to IDLE+POWERING_DOWN (%). At this time, the SuspendProgram will execute. The node is not eligible for allocation until POWERING_DOWN state is removed.
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 1 idle% c1-compute-0-0 debug* up infinite 99 idle~ c1-compute-0-[1-99]
POWER UP and POWER DOWN Failures
A node may move into DOWN state if there is a failure during the POWERING_UP or POWERING_DOWN phase. The ResumeTimeout controls how long Slurm waits until nodes are expected to register. The node is marked DOWN if it fails to register in that time and the jobs scheduled on the node are requeued. To move the node back into IDLE state, run:
scontrol update node=[nodename] state=resume
SuspendTimeout controls when Slurm will assume the node has been relinquished to the cloud. The node is marked IDLE and POWERED_DOWN at this point. This step can be accelerated by running the "scontrol update node=[nodename] state=resume" manually, or in the SuspendProgram script.
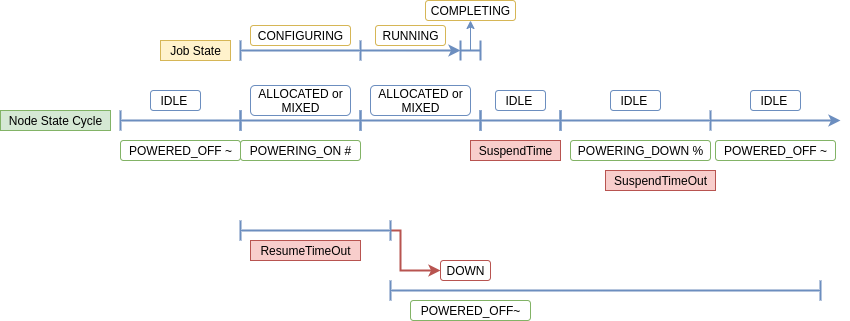
Figure 1. Node State Lifecycle
Manual Power Saving
A node can be manually powered on and off by setting the state of the node to the following states using "scontrol update":
POWER_DOWN, POWER_UP, POWER_DOWN_ASAP, or POWER_DOWN_FORCE
POWER_DOWN or POWER_UP use the configured SuspendProgram and ResumeProgram programs to explicitly place a node in or out of a power saving mode. If a node is already in the process of being powered up or down, the command will only change the state of the node but won't have any effect until the configured ResumeTimeout or SuspendTimeout is reached.
For POWER_UP, the node goes through a similar lifecycle as noted above, except it will be in IDLE state instead of MIXED or ALLOCATED as it is not allocated to a job yet.
POWER_DOWN is signified by the (!) symbol. It marks the node to be powered down as soon as no jobs are running on the node anymore. Powering down may be delayed if more jobs are scheduled to the node while it is currently running other jobs. As soon as all jobs complete on the node, the node will move to POWERING_DOWN (%).
POWER_DOWN_ASAP sets the node state as DRAINING and marks it to be powered off with the POWER_DOWN state. DRAINING allows for currently running jobs to complete, but no additional jobs will be allocated to it. When the jobs are completed, the node will move to POWERING_DOWN (%).
POWER_DOWN_FORCE cancels all jobs on the node and suspends the node immediately, placing the node in IDLE and POWER_DOWN (!) state and then POWERING_DOWN (%) state.
scontrol update nodename=c1-compute-0-0 state=power_down_asap
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 1 drng! c1-compute-0-0 debug* up infinite 99 idle~ c1-compute-0-[1-99]
Last modified 14 June 2022