Failure Management Support
Overview
Modern high performance computers can include thousands of nodes and millions of cores. The shear number of components can result in a mean time between failure measured in hours, which is lower than the execution time of many applications. In order to effectively manage such large systems, Slurm includes infrastructure designed to work with applications allowing them to manage failures and keep running. Slurm infrastructure includes support for:
- Permitting users to drain nodes they believe are failing
- A pool of hot-spare resources, which applications can use to replace failed or failing resources in their current allocation
- Extending a job's time limit to recover from failures
- Real time application notification of failures and availability of replacement resources
- Access control list control over failure management capabilities
- A library that applications can link to directly without contamination by GPL licensing
- A command line interface to these capabilities
Architecture
The failure management is implemented as a client server in which the server is a plugin in slurmctld and the client is an API that negotiate the resource management allocation from an already running job.
These are the architectural components:
- The plugin implements the server logic which keeps track of nodes allocated to jobs and job steps, the state of nodes and their availability. Having the complete view of resource allocations the server can effectively help applications to be resilient to node failures.
- libsmd.so, libsmd.a and smd.h are the client interface and library to the non stop services based on a jobID.
- smd command build on top of the library provides command line interface to failure management services. nonstop.sh shell script which automates the node replacement based on user supplied environment variables.
The controller keeps nodes in several states which reflects their usability.
- Failed hosts, currently out of service.
- Failing hosts, malfunctioning and/or expected to fail.
- Hot Spare. A cluster-wide pool of resources to be made available to jobs with failed/failing nodes. The hot spare pool can be partition based, the administrator specifies how many spares in a given partition.
Failing hosts can be drained and then dropped from the allocation, giving application flexibility to manage its own resources
Drained nodes can be put back on-line by the administrator and they will go automatically back to the spare pool. Failed nodes can be put back on-line and they will go automatically back to the spare pool.
Application usually detects the failure by itself when losing one or more of its component, then it is able to notify Slurm of failures and drain nodes. Application can also query Slurm about state of nodes in its allocation and/or asks Slurm to replace its failed/failing nodes, then it can
- Wait for nodes become available, eventually increasing its runtime till then
- Increase its runtime upon node replacement
- Drop the nodes and continue, eventually increasing its runtime
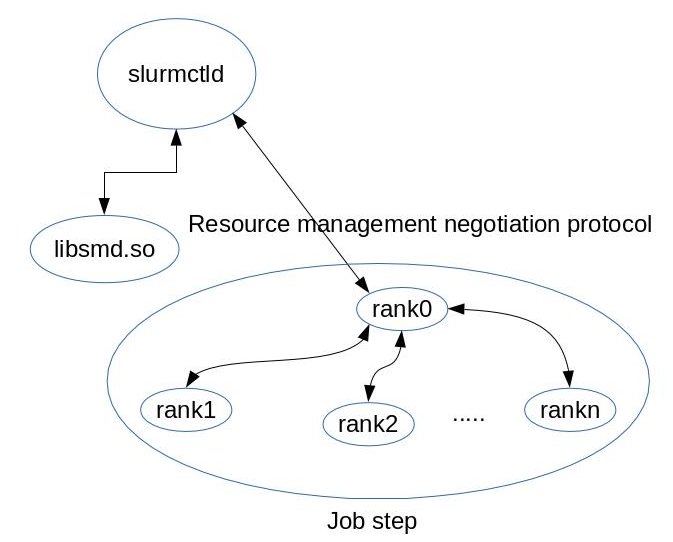
The figure 1 shows the component interaction.
- The job step. Rank 0 is the rank responsible for monitoring the state of other
ranks, it then negotiates with the controller resource allocation in case of failure.
There are two ways in which rank 0 interacts with the controller:
- Using a command that detects failure and generates a new hostlist for the application.
- Link with the smd library and subscribe with the controller for events.
- The slurmctld process itself which loads the failure management plugin.
- The failure management plugin itself. The plugin talks to the smd library over a tcp/ip connection.
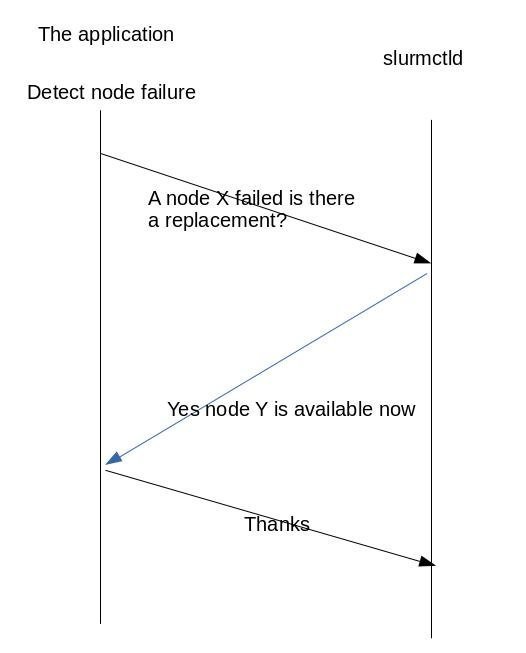
The figure 2 show a simple protocol interaction between the application and the controller. In this case the application detects the failure by itself so the job steps terminates. The application then asks for a node replacement either using the smd command with appropriate parameters or via an API call. In this specific example the controller allocates a new node to the application which can then initiates a new job step.
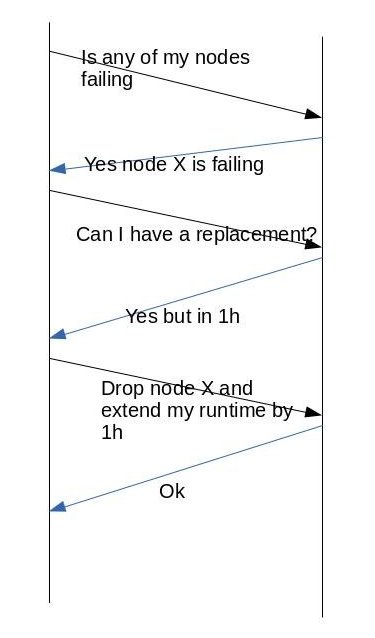
The figure 3 shows more complex protocol negotiation. In this case the application query the controller to check if any node in the step has failed, then ask for replacement which is available in 1 hour. The application then decides to drop the node and keep running with less resources but having its runtime extended by 1 hour.
Configuration
Slurm's slurmctld/nonstop plugin acts as the server for these functions. Configure in slurm.conf as follows:
SlurmctldPlugstack=slurmctld/nonstop
This plugin uses a nonstop.conf file for it's configuration details. See "man nonstop.conf" for details about the options. The nonstop.conf file must be in the same directory as your slurm.conf file. A sample nonstop.conf file appears below.
# # Sample nonstop.conf file # # Same as BackupAddr in slurm.conf BackupAddr=bacco # Same as ControlAddr in slurm.conf ControlAddr=prometeo # Verbosity of plugin logging Debug=0 # Count of hot spare nodes in partition "batch" HotSpareCount=batch:8 # Maximum hot spare node use by any single job MaxSpareNodeCount=4 # Port the slurmctld/nonstop plugin reads from Port=9114 # Maximum time limit extension if no hot spares TimeLimitDelay=600 # Time limit extension for each replaced node TimeLimitExtend=2 # Users allowed to drain nodes UserDrainAllow=alan,brenda
An additional package named smd will also need to be installed. This package is available at no additional cost for systems under a support contract with SchedMD LLC (including support contracts procured through other vendors of Slurm support such as Bull and Cray). Please contact the appropriate vendor for the software.
The smd package includes a library and command line interface, libsmd and smd respectively. Note that libsmd is not under the GPL license and can be link by other programs without those programs needing to be released under a GPL license.
Commands and API
In this paragraph we examine the user interaction with the system. As stated previously users can use the smd command or the API.
The smd command is driven by command line options, see smd man page for more details. However the smd command can also be driven by environment variables which makes it easier to be deployed in user applications. The environment variables describes what action to take upon host failure or if the host is failing.
The environmental variables to set are SMD_NONSTOP_FAILED or SMD_NONSTOP_FAILING they control the controller actions when a node failed or it is failing.
The variables can take the following values based on the desired action.
- REPLACE
Replace the failed/failing nodes. - DROP Drop the nodes from the allocation.
- TIME_LIMIT_DELAY=Xmin
If a job requires replacement resources and none are immediately available, then permit a job to extend its time limit by the length of time required to secure replacement resources up to the number of minutes specified. - TIME_LIMIT_EXTEND=Ymin
Specifies the number of minutes that a job can extend its time limit for each replaced node. - TIME_LIMIT_DROP=Zmin
Specifies the number of minutes that a job can extend its time limit for each failed or failing node removed from the job's allocation. - EXIT_JOB
Exit the job upon node failure.
The variables can be combined in to logical and expressions.
- SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=4:EXIT_JOB
This directive instructs the smd command to attempt to replace failed/failing nodes, if replacement is not immediately available wait up to 4 minutes, then if still not available exit the job. - SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=4:DROP:TIME_LIMIT_DROP=10
This instructs smd command to attempt to replace nodes with a 4 minutes timeout, then drop the failed nodes and extend the step runtime by 10 minutes.
Example
In this use case analysis we illustrate how to use the nonstop.sh and steps.sh script provided with the failure management package. The steps.sh is the Slurm batch script that executes job steps.
Its main loop looks like this:
for ((i = 1; i <= $num; i++))
do
# Run the $i step of my application
srun -l --mpi=pmi2 $PWD/star -t 10 > /dev/null
# After each step invoke the snonstop.sh script
# which will detect if any node has failed and
# will execute the actions specified by the user
# via the SMD_NONSTOP_FAILED variable
$PWD/nonstop.sh
if [ $? -ne 0 ]; then
exit 1
fi
echo "start: step $i `date`"
done
Let's run several tests, in all test we submit the batch jobs as sbatch steps.sh. Note The batch job must use the --no-kill option to prevent Slurm from terminating the entire batch job upon one step failure.
- Set SMD_NONSTOP_FAILED="REPLACE"
- Setting num=2 to run only 2 steps.
- With no host failure the job will run to completion and the nonstop.sh
will print to its stdout the status of the nodes in the allocation.
start: step 0 Fri Mar 28 11:47:19 PDT 2014 is_failed: job 58 searching for FAILED hosts is_failed: job 58 has no FAILED nodes start: step 1 Fri Mar 28 11:47:55 PDT 2014 is_failed: job 58 searching for FAILED hosts is_failed: job 58 has no FAILED nodes
- Set SMD_NONSTOP_FAILED="REPLACE
- Setting num=10 to run 10 steps.
- As the job starts set one of the execution nodes down using the
scontrol command. As soon as the running step finishes the nonstop.sh
runs instructing the smd command to detect node failure and ask
for replacement. The script stdout is:
is_failed: job 59 searching for FAILED hosts is_failed: job 59 has 1 FAILED nodes is_failed: job 59 FAILED node ercole cpu_count 1 _handle_fault: job 59 handle failed_hosts _try_replace: job 59 trying to replace 1 nodes _try_replace: job 59 node ercole replaced by prometeo _generate_node_file: job 59 all nodes replaced
- Examine the output of sinfo--format="%12P %.10n %.5T %.14C" command.
->sinfo PARTITION HOSTNAMES STATE CPUS(A/I/O/T) markab* dario mixed 1/15/0/16 markab* prometeo mixed 1/15/0/16 markab* spartaco idle 0/16/0/16 markab* ercole down 0/0/16/16
From the output we see the initial host ercole which went down was replaced by the host prometeo.
- Set SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=1:DROP:TIME_LIMIT_DROP=30"
- Modify steps.sh to run on all available nodes so when a node fails there is no replacement available.
- Upon the node failure the system will try for one minute to get a
replacement after that period of time will drop the node and extend the
job's runtime. This time the stdout is more verbose.
is_failed: job 151 searching for FAILED hosts is_failed: job 151 has 1 FAILED nodes is_failed: job 151 FAILED node spartaco cpu_count 1 _handle_fault: job 151 handle failed_hosts _try_replace: job 151 trying to replace 1 nodes _try_replace: smd_replace_node() error job_id 151: Failed to replace the node _time_limit_extend: job 151 extending job time limit by 1 minutes _increase_job_runtime: job 151 run time limit extended by 1min successfully _try_replace: job 151 waited for 0 sec cnt 0 trying every 20 sec... _try_replace: job 151 trying to replace 1 nodes _try_replace: smd_replace_node() error job_id 151: Failed to replace the node _try_replace: job 151 waited for 20 sec cnt 1 trying every 20 sec..._try_replace: smd_replace_node() error job_id 151: Failed to replace the node _try_replace: job 151 waited for 40 sec cnt 2 trying every 20 sec... _try_replace: job 151 failed to replace down or failing nodes: spartaco _drop_nodes: job 151 node spartaco dropped all right _generate_node_file: job 151 all nodes replaced source the /tmp/smd_job_151_nodes.sh hostfile to get the new job environment _time_limit_extend: job 151 extending job time limit by 30 minutes _increase_job_runtime: job 151 run time limit extended by 30min successfully
As instructed the system tried to replace the failed node for a minute, then it drop the node and extended the runtime for 30 minutes. The extended runtime must be within the system TimeLimitDrop configured in nonstop.conf.
The job step acquires the new environment from the hosts file smd_job_$SLURM_JOB_ID_nodes.sh which is created by the smd command in /tmp on the node where the batch script runs.
export SLURM_NODELIST=dario,prometeo export SLURM_JOB_NODELIST=dario,prometeo export SLURM_NNODES=2 export SLURM_JOB_NUM_NODES=2 export SLURM_JOB_CPUS_PER_NODE=2\(x2\) unset SLURM_TASKS_PER_NODE
This environment is sourced by the steps.sh script so the next job steps will run using the new environment.
Last modified 21 June 2017